There is no doubt that PostgreSQL is the best operational engine for modern business. For three years in a row, developers have named it the "Most Admired" database. It is now the main operational engine for more than half of all professional engineering teams.
However, despite this dominance, when scaling, PostgreSQL suffers from rigid physical limits. Because standard Postgres relies on a single primary node for transactional integrity, you cannot simply "add parallel VMs" to scale write throughput without introducing complex, manual sharding.
This limitation has become critical with the rise of AI Agents and Retrieval-Augmented Generation (RAG). To act with precision, AI agents need immediate access to fresh context. They cannot afford the latency of stale data caused by syncing transactions to external vector stores like Pinecone or Elasticsearch. They need a unified engine where the "analytical brain" sees updates the moment they happen.
Naturally, developers turned to the pgvector extension to solve this, making Postgres the hero again. Why manage a new database when we can just use the one we know?
But there is a catch. Asking a single primary node to run heavy vector similarity searches while simultaneously processing core business transactions creates a "noisy neighbor" crisis at the hardware level.
Because standard Postgres relies on a shared buffer cache (the RAM where "hot" data lives), massive HNSW index traversals effectively "poison" the cache, flushing your core transactional data to slow disk storage, and causing the whole system to lag.
You cannot solve this by simply "adding more nodes"; while read-replicas can handle queries, the single Primary Node still shoulders the entire burden of writing and indexing these heavy vectors. To scale this model, we need cloud-native architectures that fundamentally decouple storage from compute.
To scale this "Postgres-as-everything" model without crashing the primary node, we need cloud-native architectures that fundamentally re-engineer the database.
Microsoft and Databricks are responding with two very different interpretations of what “PostgreSQL at scale” should mean.
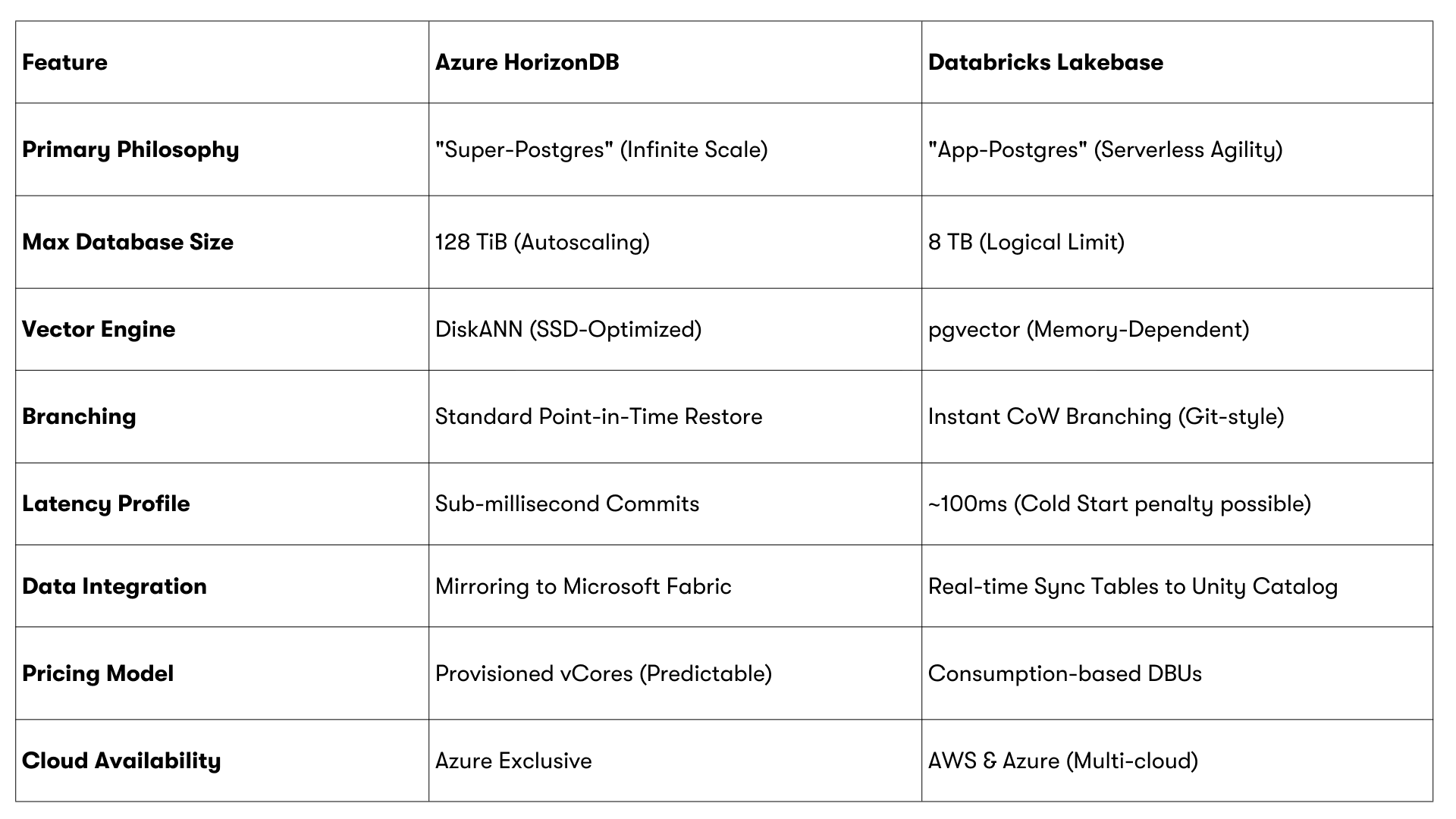
Azure HorizonDB represents a Super-Postgres approach, a ground-up re-engineering PostgreSQL using disaggregated storage and a Rust-based engine to run as a massive, durable system of record with built-in AI and vector capabilities.
Databricks Lakebase represents an App-Postgres approach leveraging Neon (acquired by Databricks mid 2025)’s serverless technology to treat PostgreSQL as a flexible, serverless state layer embedded inside the Lakehouse and optimized for data and AI applications.
They address the same problem space but with fundamentally different priorities. The real question is not which platform is more powerful. It is the role PostgreSQL is expected to play in your architecture.
HorizonDB is designed for environments where PostgreSQL is the primary storage of transaction records, and the business requires fast transactional performance. It is designed to remove the vertical scaling limits of regular Postgres without losing consistency, durability, or predictable latency.
How it works:
Separate Compute & Storage: It sends Write-Ahead Log (WAL) records to a distributed storage layer across multiple zones, which improves performance for long-term transactional load.
Non-Blocking Writes: When there is a lot of write traffic, the database node doesn't stop to write big data pages to disk like it does in regular Postgres.
Lightweight Commits: The storage layer takes care of page materialization, which is outside the critical path. This keeps commit latency low even when many users are using the system at the same time.
This approach prioritizes consistent performance under heavy load. HorizonDB is built to handle high write concurrency, large operational datasets, and a steady stream of transactions without requiring application teams to add sharding logic or compromise consistency guarantees.
The result is a PostgreSQL platform that provides cloud-native elasticity without sacrificing ACID compliance. It should be stable, reliable, and resilient enough to support applications where downtime, latency spikes, or data discrepancies directly impact trust or revenue.
Lakebase is designed for environments where PostgreSQL supports applications rather than anchoring them. The Databricks Lakehouse has a serverless PostgreSQL engine that is managed and built right in. This makes it easier to work with operational data, analytics, and machine learning.
How it works:
Page-Server Architecture: Compute is separated from storage using a page-server model that is backed by object storage.
Ephemeral Compute: Infrastructure is fully serverless, using a copy-on-write architecture that allows for "zero-copy" database branching. This lets developers (or AI agents) spin up isolated, full-state clones of production data in seconds without the storage overhead or IO cost of a physical copy.
Lakehouse Integration: Transactional state shares governance, lineage, and lifecycle with analytics workloads.
This approach prioritizes being able to adapt quickly and easily. Applications can write transactional state while still being part of the same governance, lineage, and data lifecycle as analytics workloads.
The result is a PostgreSQL platform that acts more like an application service than a fixed infrastructure. It is lightweight, adaptable, and made for teams that want to iterate and get feedback quickly. Lakebase is most useful when PostgreSQL serves as a conduit between applications, analytics, and AI rather than as a singular endpoint.
HorizonDB’s scaling model is designed to be predictable. It aims to maintain consistent performance as user count and data volume grow by scaling compute horizontally and using shared storage. This model reduces operational surprises and is best suited to workloads with known performance requirements that will last a long time.
The trade-off is that change tends to be more deliberate. Planning and operational discipline pay off with HorizonDB. It works well in environments where schemas don't change often, and performance needs to stay consistent.
Lakebase emphasizes speed. Serverless compute allows workloads to scale up and down as needed, and environments can be established or modified quickly. This helps teams that need to move quickly, test ideas, and adapt systems frequently.
The trade-off is that Lakebase isn't meant to push transactional throughput to its limits. It focuses on how quickly things can change instead of how long they can stay the same.
The distinction here is less about capability and more about tolerance. HorizonDB makes things less variable. Lakebase makes things as flexible as possible.
HorizonDB is positioned for very large databases and high connection counts. Microsoft has publicly stated support for up to 128 TiB of autoscaling storage and very high aggregate compute. While data can be exported or consumed downstream, HorizonDB is not designed to be transient or ephemeral.
This makes the database itself less complicated. The system is still more concerned with correctness, durability, and performance than with data orchestration. It is meant to help big, centralized systems that have evolved over time and can't be easily broken down. HorizonDB is a good choice for moving big, long-lasting systems like ERP platforms, core financial ledgers, or global inventory systems.
Lakebase works better with smaller, more specialized datasets that are often found in new applications and data products. As it stands now, it has a 8 TB logical limit per instance, which means it can't be used for substantial lift-and-shift migrations of monolithic systems.
Instead, Lakebase assumes PostgreSQL will be part of a broader ecosystem. Under shared governance, transactional state, analytical features, and AI models all work together. This makes it easier to design data-driven apps, but also means you have to think about how to run things in a new way.
Vector search is one of the most meaningful technical differentiators between the two platforms.
HorizonDB integrates DiskANN, a disk-based vector indexing engine developed by Microsoft Research. DiskANN allows most of the vector index to reside on fast NVMe SSDs rather than entirely in memory.
In practice, this enables HorizonDB to support vector datasets 10–50× larger than available RAM while maintaining low latency.
HorizonDB enables single-step, filter-aware vector search (also known as predicate pushdown). Instead of the common 'search-then-filter' approach that leads to empty results or high latency, HorizonDB applies business constraints, e.g., like region, price, or permissions, directly during the graph traversal. This ensures high recall and consistent performance, even on highly selective metadata filters.
The outcome is that HorizonDB can act as both a transactional database and a large-scale semantic search engine for core application data.
Lakebase takes a more compositional approach. It supports vectors using standard PostgreSQL extensions, such as pgvector, which is well-suited for application-level embeddings, such as sessions, conversations, or recent activity. For very large knowledge bases or enterprise-wide retrieval, Databricks expects teams to use dedicated vector search services in the Lakehouse alongside Lakebase.
The outcome is a clear separation of responsibilities. HorizonDB aims to make PostgreSQL do more. Lakebase assumes PostgreSQL will be composed with specialized services as scale grows.
Both HorizonDB and Lakebase can support AI-driven applications, but they assume different AI operating models.
HorizonDB fits scenarios where AI augments trusted systems.
Intelligence lives close to the transactional state with ACID-compliant reliability. This works well for fraud detection, recommendations, or decision support embedded directly into systems of record.
Lakebase fits scenarios where experimentation is constant.
Its copy-on-write branching model allows teams and AI agents to create isolated database branches instantly. An agent can simulate actions, evaluate outcomes, and either merge changes or discard the branch entirely.
This makes Lakebase a great place for agentic AI, where you need to safely and cheaply sandbox behavior that isn't always predictable.
The right choice depends less on features and more on the role PostgreSQL plays in your architecture.
You are migrating or running a large, mission-critical system of record, where PostgreSQL stores authoritative business data and downtime or inconsistency has a direct financial or operational impact.
You need consistent performance even under high sustained load, especially for workloads that are always on and write-intensive, where latency spikes are not acceptable.
You want large-scale vector search inside the database, using DiskANN to support semantic search combined with strict business filters without having to set up a separate vector store.
You are deeply invested in Azure and Microsoft Fabric, and want tight integration with Fabric analytics, Entra ID, and Microsoft’s data and AI tooling.
You are building AI or data-driven applications, where PostgreSQL supports the application rather than defining the system of record.
You want to be able to analyze and train models on transactional data without having to deal with complicated pipelines.
You need to give your developers or AI agents a way to test out changes or simulations safely and inexpensively without putting production data at risk.
You have spiky or intermittent workloads, and you may save money when systems are not in use by employing serverless, scale-to-zero behavior.
When both options are possible, roadmap pressure generally breaks the tie. HorizonDB is a safer choice if future expansion will push transactional limits. If future growth depends on insight and experimentation, Lakebase offers more leverage. Many mature architectures will ultimately use both, each aligned to the role it performs best.
If you’re evaluating HorizonDB, Lakebase, or a hybrid approach and want an objective view, C60Digital works with teams to map workloads to the right data architecture, validate trade-offs, and design platforms that scale with both operational and AI demands.
Whether you’re modernizing a system of record, building AI-driven applications, or deciding how these platforms fit together, get in touch with our experts to move from comparison to execution with confidence.